Home | Software | Analisi | Links | Glossario | Bibliografia
Il processo di scoperta dei modelli di navigazione è stato realizzato attraverso le due tecniche più comuni di Web Usage Mining, vale a dire le regole associative e sequenze ed il clustering.
Il software WUM, con l'ausilio del linguaggio di web mining MINT , permette di calcolare gli indici di support e di confidence per le varie pagine del sito.
A tal fine sono state eseguite delle query in linguaggio MINT del tipo:
select t from node as a b, template a * b as t
where a.url startswith "documenti"
and b.url !startswith "documenti"
and a.occurrence = 1
and b.occurrence = 1
and ( b.support / a.support ) >= 0.1
and a.support > 5
Andiamo a descrivere cosa mette in pratica la query precedente. Vengono selezionate tutte le sequenze t tra le pagine a e b , in particolare le pagine a e b devono riguardare due aree diverse del sito, in questo caso si vanno a scoprire le sequenze tra le pagine relative all'area “documenti” e quelle relative alle altre aree. Questo è espresso dai primi due vincoli.
Il terzo ed il quarto vincolo impongono che le pagine compaiano una sola volta nel percorso di navigazione. In questo modo consideriamo come significative sia le sessioni che le sottosessioni ( subsessions ) dei diversi percorsi di navigazione. In pratica vogliamo dare rilevanza non solo alle intere sessioni, ma anche alle diverse parti di una singola sessione.
Il quinto vincolo richiede che l'indice di confidence tra le due pagine sia pari almeno al 10% affinché la sequenza possa considerarsi significativa. Nell'ambito del software WUM tale indice coincide con l' efficienza di conversione descritta nel paragrafo 3.9 del capitolo precedente.
L'ultimo vincolo riguarda l'indice di support e specifica che la pagina a deve essere stata visitata in almeno 6 sessioni, questo al fine di evitare che si prendano in considerazione percorsi con un alto livello di confidence poiché sono molto rari.
Nella tabella seguente vengono riportati i risultati dell'analisi, ordinati per livello di confidence. Tra parentesi si riportano i nomi dei file.
Pagina a |
Pagina b |
Confidence (%) |
|---|---|---|
organizzazione.servizi.informatici (inf.htm) |
documenti.lavoro.internet.sito (intra/intranet.htm) |
30,2 |
organizzazione.servizi.informatici (inf.htm) |
documenti.cronologico (crono.htm) |
30,0 |
informazioni.medicina.servizi (sermed.htm) |
risorse.elettroniche.areadisciplinare (erdisci.htm) |
27,2 |
organizzazione.servizi.pubblico (pre.htm) |
documenti.ufficiali.cartaservizi.2003 (cartaservizi.htm) |
25,9 |
informazioni.medicina.servizi.old (med.htm) |
catalogo.repertorio.periodici.indice (repertorio/repertorio.htm) |
25,1 |
organizzazione.acquisizioni (acq.htm) |
informazioni.prestito. interbibliotecario (faqill.htm) |
25,1 |
organizzazione.acquisizioni (acq.htm) |
informazioni.ricerchebibliografiche (faqref.htm) |
24,8 |
organizzazione.servizi.pubblico (pre.htm) |
informazioni.prestito.domicilio (faqpre.htm) |
22,2 |
organizzazione.periodici (per.htm) |
documenti.lavoro.progetto.serse (serse.htm) |
21,0 |
catalogo.repertorio.periodici.indice (repertorio/repertorio.htm) |
risorse.elettroniche.indice (journal/ej_intro.asp ) |
21,0 |
statistiche.web.2003.menu (/STATISTICHE/ Report2003/menu.htm) |
internet.bibliolink (biblink.htm) |
20,2 |
informazioni.medicina.scheda (bibliou8.htm) |
risorse.elettroniche.areadisciplinare (erdisci.htm) |
20,0 |
organizzazione.servizi.pubblico (pre.htm) |
informazioni.ricerchebibliografiche (faqref.htm) |
18,5 |
organizzazione.servizi.pubblico (pre.htm) |
informazioni.consultazione (faqcons.htm) |
18,2 |
organizzazione.scienze (sci.htm) |
informazioni.ricerchebibliografiche (faqref.htm) |
18,1 |
documenti.lavoro.internet.sito (intra/intranet.htm) |
statistiche.indice (stat.htm) |
17,5 |
organizzazione.scienze (sci.htm) |
risorse.elettroniche.indice (journal/ej_intro.asp ) |
17,5 |
catalogo.periodici.alfabetico (elenco/intro.htm) |
organizzazione.periodici (per.htm) |
17,4 |
organizzazione.scienze (sci.htm) |
risorse.elettroniche.areadisciplinare (erdisci.htm) |
16,7 |
organizzazione.organigramma (orga.pdf) |
statistiche.indice (stat.htm) |
16,7 |
informazioni.medicina.servizi.old (med.htm) |
catalogo.periodici.alfabetico.j (elenco/J.HTM) |
16,6 |
catalogo.stone.indice (stone/stone.htm) |
risorse.elettroniche.areadisciplinare (erdisci.htm) |
16,6 |
informazioni.centrale.piantina.livello.2 (piantina/index2.html) |
risorse.elettroniche.basididati (ertipo.htm) |
16,3 |
catalogo.stone.indice (stone/stone.htm) |
informazioni.regolamento (regolamento.htm) |
16,2 |
informazioni.ricerchebibliografiche (faqref.htm) |
risorse.elettroniche.areadisciplinare (erdisci.htm) |
16,1 |
informazioni.centrale.piantina. classi.cdd.indice (piantina/tabella.html) |
documenti.lavoro.cdd.progetto (intra/progcdd.htm) |
16,0 |
statistiche.web.2003.menu (/STATISTICHE/ Report2003/menu.htm) |
internet.percorsi (xcorsi.htm) |
15,8 |
informazioni.prestito.domicilio (faqpre.htm) |
documenti.ufficiali.cartaservizi.2003 (cartaservizi.htm) |
15,1 |
organizzazione.servizi.pubblico (pre.htm) |
internet.percorsi (xcorsi.htm) |
14,8 |
documenti.ufficiali.cartaservizi.attuale (cartaservizi.pdf) |
informazioni.regolamento (regolamento.htm) |
13,3 |
statistiche.indice (stat.htm) |
risorse.elettroniche.areadisciplinare (erdisci.htm) |
13,3 |
informazioni.ricerchebibliografiche (faqref.htm) |
risorse.elettroniche.basididati (ertipo.htm) |
12,9 |
documenti.lavoro.istruzioni. collocazione (intra/istrucol.htm) |
informazioni.consultazione (faqcons.htm) |
12,6 |
risorse.elettroniche.indice (journal/ej_intro.asp) |
catalogo.periodici.alfabetico (elenco/intro.htm) |
12,6 |
informazioni.foto (foto.htm) |
organizzazione.servizi.pubblico (pre.htm) |
12,5 |
documenti.lavoro.istruzioni. collocazione (intra/istrucol.htm) |
catalogo.periodici.alfabetico (elenco/intro.htm) |
12,5 |
informazioni.ricerchebibliografiche (faqref.htm) |
internet.percorsi (xcorsi.htm) |
12,2 |
risorse.elettroniche.indice (journal/ej_intro.asp) |
internet.bibliolink (biblink.htm) |
11,7 |
documenti.ufficiali.accordi (accordi.htm) |
informazioni.consultazione (faqcons.htm) |
11,6 |
internet.percorsi (xcorsi.htm) |
risorse.elettroniche.basididati (ertipo.htm) |
11,6 |
catalogo.periodici.alfabetico (elenco/intro.htm) |
risorse.elettroniche.indice (journal/ej_intro.asp ) |
11,2 |
internet.percorsi (xcorsi.htm) |
documenti.lavoro.internet.sito (intra/intranet.htm) |
11,2 |
statistiche.indice (stat.htm) |
internet.percorsi (xcorsi.htm) |
10,8 |
internet.link.utenti (yourlink.htm) |
risorse.elettroniche.basididati (ertipo.htm) |
10,8 |
risorse.elettroniche.ricerca.area (journal/source.asp) |
internet.bibliolink (biblink.htm) |
10,6 |
documenti.ufficiali.accordi (accordi.htm) |
informazioni.regolamento (regolamento.htm) |
10,5 |
catalogo.repertorio.periodici.indice (repertorio/repertorio.htm) |
risorse.elettroniche.basididati (ertipo.htm) |
10,5 |
internet.link.utenti (yourlink.htm) |
risorse.elettroniche.indice (journal/ej_intro.asp ) |
10,5 |
internet.bibliolink (biblink.htm) |
risorse.elettroniche.areadisciplinare (erdisci.htm) |
10,3 |
catalogo.repertorio.periodici.indice (repertorio/repertorio.htm) |
internet.bibliolink (biblink.htm) |
10,2 |
Tabella 4.1 – Sequenze di pagine con livelli significativi di confidence
Una prima indicazione che questo tipo di analisi suggerisce riguarda la creazione di collegamenti ( link ) dalle pagine a alle relative pagine b . In questo modo l'accesso alle pagine correlate risulta semplificato. Ricordiamo che lo scopo principale dell'analisi di Web Usage Mining è rappresentato dal miglioramento del sito dal punto di vista degli utenti.
Il Web Usage Mining può essere utilizzato anche per sviluppare opportune strategie di prefetching e caching in modo da ridurre il tempo di risposta del server. Il prefetching è una caratteristica del browser che permette ad una pagina HTML di recuperare altri contenuti web quando la connessione del browser dell'utente è inattiva. Il contenuto del prefetching viene immagazzinato nella cache del browser ed appare quindi velocemente non appena l'utente accede alla pagina che contiene il contenuto immagazzinato.
L'ulteriore suggerimento che si può indicare è quello di inserire in ogni pagina a l'istruzione in linguaggio HTML per recuperare il contenuto della relativa pagina b . L'istruzione dovrà essere inserita all'inizio del documento e risulterà del tipo:
<link rel="prefetch" href="document.html">
Sostituendo opportunamente al file di esempio “document.html” i nomi delle relative pagine b . Ad esempio nella pagina a “inf.htm” si aggiungerà l'istruzione ( cfr. prima riga della tabella precedente):
<link rel="prefetch" href=" intra/intranet.htm ">
In questo modo, mentre l'utente legge il contenuto della pagina relativa ai servizi informatici (inf.htm), il browser preparerà nella sua cache la pagina relativa al documento di lavoro riguardante il sito internet (intra/intranet.htm). Il contenuto della pagine memorizzata apparirà quindi velocemente se l'utente la richiederà.
L'analisi cluster permette di raggruppare utenti con caratteristiche simili in base ai diversi percorsi di navigazione. Si è dunque interessati ad individuare i diversi segmenti comportamentali.
L'input fondamentale per ogni analisi cluster è rappresentato dalla matrice dei dati. Per ottenere tale matrice è stato necessario rielaborare, attraverso una applicazione Java creata ad hoc , i dati esportati dal software WUM.
I dati esportati dal software si presentano in questo modo:
Figura 4.8 – Esportazione dal software WUM
Descriviamo brevemente cosa rappresentano i campi:
• session: codice della sessione
• visitor: codice del visitatore
• t_occ: numero delle pagine visitate fino a quel punto della sessione
• p_id: codice della pagina
• p_occ: numero delle pagine visitate per una particolare area del sito
• p_url: nome dell'area del sito a cui appartiene la pagina visitata
In particolare, il nostro interesse riguarda solamente i campi session , visitor , p_occ e p_url . Attraverso la rielaborazione tramite l'applicazione Java “reOrganizeTable” si ottiene la matrice di dati, uno stralcio della quale è rappresentato nella figura seguente:
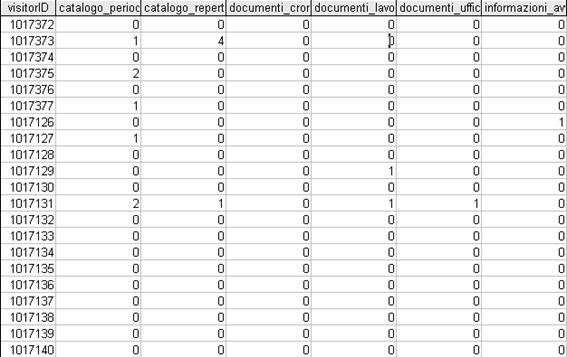
Figura 4.9 – Stralcio della matrice dei dati
Le righe della matrice rappresentano i diversi visitatori, le colonne rappresentano le diverse aree del sito. Si noti che in corrispondenza di ciascuna area di pagine si ha una variabile discreta, che mostra il numero di visite effettuato da ciascun visitatore all'area considerata. Per mancanza di spazio, nella figura di esempio vengono visualizzate solamente 6 delle 32 aree considerate. Si riportano nella tabella seguente le 32 aree analizzate:
catalogo.periodici |
catalogo.repertorio.periodici |
catalogo.stone |
documenti.cronologico |
documenti.lavoro |
documenti.ufficiali |
home.homepage |
informazioni.avvisi.archivio |
informazioni.avvisi.attuali |
informazioni.avvisi.collaborazioni |
informazioni.avvisi.notizie |
informazioni.avvisi.software |
informazioni.chisiamo |
informazioni.consultazione |
informazioni.foto |
informazioni.generali |
informazioni.medicina |
informazioni.opac |
informazioni.prestito.domicilio |
informazioni.prestito.interbibliotecario |
informazioni.regolamento |
informazioni.ricerchebibliografiche |
informazioni.scienze |
informazioni.whoweare |
internet.bibliolink |
internet.cercagoogle |
internet.link.utenti |
internet.percorsi |
internet.webstory |
organizzazione |
risorse.elettroniche |
statistiche |
Tabella 4.2 – Aree considerate
I dati così elaborati vengono importati nel software statistico SPSS . Per individuare i diversi segmenti comportamentali si utilizza la procedura TwoStep Cluster Analysis . L'algoritmo impiegato in questa procedura possiede diverse caratteristiche desiderabili che lo differenziano dalle tecniche tradizionali di clustering. In particolare, è un algoritmo scalabile che ha la capacità di creare cluster basandosi sia su variabili categoriche che continue, un ulteriore vantaggio è rappresentato dal fatto che il numero di cluster viene selezionato automaticamente.
Andiamo ad osservare i risultati dell'analisi. La procedura trova 5 differenti cluster. Per prima cosa andiamo a vedere come si distribuiscono gli N =3411 visitatori all'interno dei cluster trovati.
| N | % del totale | ||
|---|---|---|---|
| Cluster | 1 | 1288 | 37,8% |
| 2 | 599 | 17,6% | |
| 3 | 463 | 13,6% | |
| 4 | 543 | 15,9% | |
| 5 | 518 | 15,2% | |
| Combinati | 3411 | 100,0% | |
| Totale | 3411 | 100,0% | |
Tabella 4.3 – Distribuzione delle osservazioni all'interno dei cluster
Per una migliore visualizzazione rappresentiamo la distribuzione all'interno di un diagramma a torta:
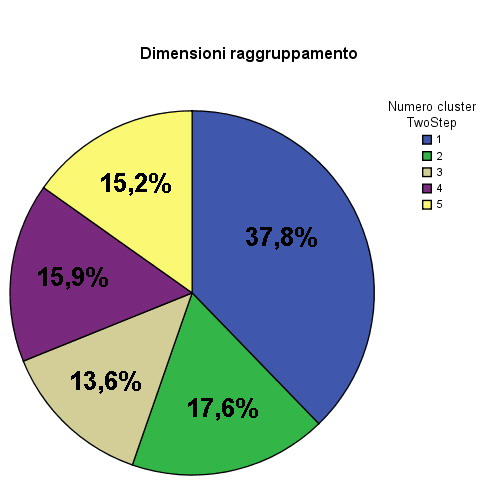
Figura 4.10 – Diagramma delle dimensioni del raggruppamento
Andiamo ora a presentare i grafici dei diversi segmenti comportamentali, in ascissa viene calcolata la statistica chi-quadrato di Pearson che rappresenta l'importanza di ciascuna variabile all'interno dello specifico cluster.
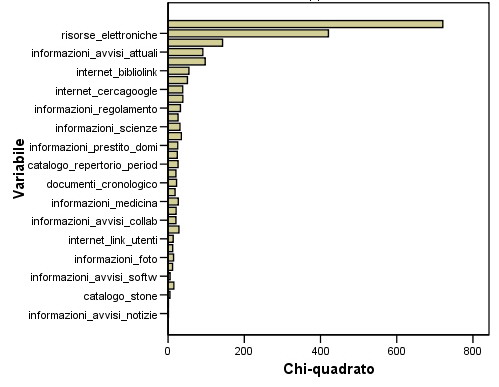
Figura 4.11 – Cluster 1
Segmento 1: “Ricercatori informatizzati”: i componenti di questo gruppo sono caratterizzati da un utilizzo del sito rivolto soprattutto alla navigazione di pagine relative alle risorse elettroniche. Sono inoltre interessati anche ai cataloghi delle riviste cartacee possedute dalla biblioteca e tendono a rimanere aggiornati tramite il frequente accesso agli avvisi e alle altre pagine di informazione. Probabilmente una buona parte di questo gruppo è rappresentata da docenti, ricercatori, dottorandi e tesisti.
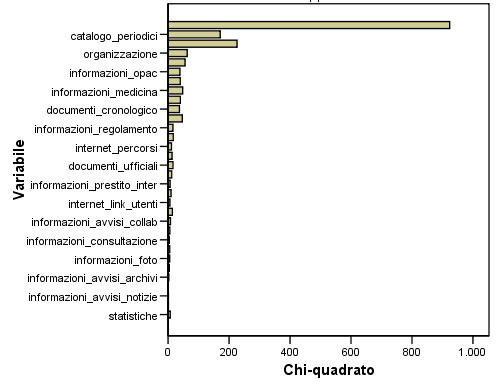
Figura 4.12 – Cluster 2
Segmento 2: “Ricercatori tradizionali”: questi utenti accedono principalmente al catalogo dei periodici cartacei posseduti dalla biblioteca. Sono inoltre interessati all'organizzazione della biblioteca e alle informazioni relative al catalogo OPAC. Si noti che molti accedono anche alle informazioni sulla sede di medicina, ciò può far supporre che una buona parte degli utenti di questo gruppo facciano parte della Facoltà di Medicina. Probabilmente anche questo gruppo è formato principalmente da docenti, ricercatori, dottorandi e tesisti.
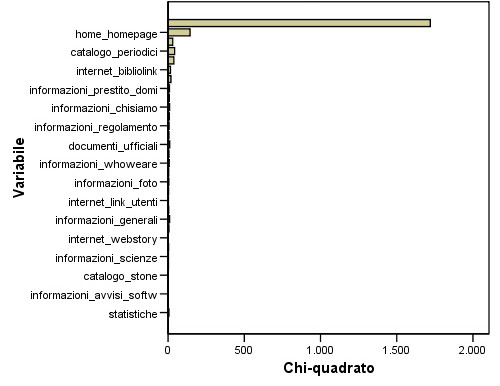
Figura 4.13 – Cluster 3
Segmento 3: “Diretti all'OPAC”: i navigatori appartenenti a questo gruppo sono accomunati dal fatto di visitare quasi esclusivamente l'home page del sito. Questo significa che con ogni probabilità essi accederanno successivamente al catalogo OPAC, per ricercare monografie o periodici posseduti dalla biblioteca. Ricordiamo che il catalogo OPAC non è compreso nella nostra analisi. Si può notare il fatto che oltre alla home page le pagine con maggiore accesso siano il catalogo periodici e la pagina dei link, forse per estendere la loro ricerca alle altre biblioteche. Si può supporre che questo gruppo sia formato principalmente dagli studenti universitari.
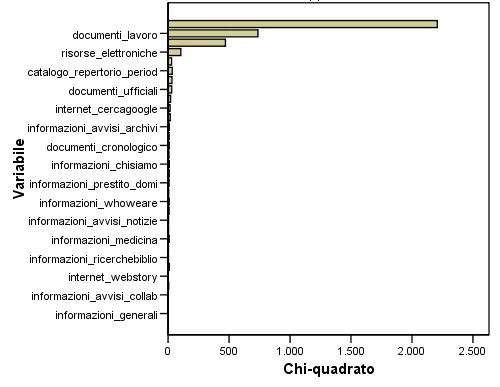
Figura 4.14 – Cluster 4
Segmento 4: “Bibliotecari”: è evidente che gli appartenenti a tale gruppo siano in qualche modo dei professionisti che lavorano in ambito bibliotecario. Essi hanno una frequentazione media estremamente alta delle pagine riguardanti i documenti di lavoro. Costoro potrebbero essere visti come persone legate al sito per motivi di lavoro, probabilmente molti di essi operano in altre biblioteche ed accedono ai documenti per informarsi e per avere dei punti di riferimento.
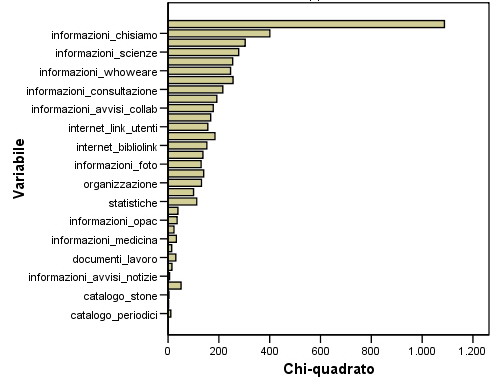
Figura 4.15 – Cluster 5
Segmento 5: “Curiosi”: è il gruppo di utenti che sfruttano le aree informative del sito. La loro navigazione avviene principalmente sulle pagine riservate alle informazioni generali, sulle pagine relative all'organizzazione della biblioteca, sulle pagine relative alle statistiche e su quelle preposte a fornire link ad altri siti di interesse. Questo gruppo di utenti potrebbe essere composto per lo più da studenti universitari o da aspiranti tali, ma non è da escludere che anche professionisti legati al mondo delle biblioteche possano appartenere a questo gruppo.
L'analisi cluster condotta, e la conseguente divisione in gruppi di visitatori, ci suggerisce di creare dei percorsi personalizzati per i cinque diversi tipi di utente. Le pagine di ciascun gruppo dovrebbero venire collegate reciprocamente attraverso l'inserimento di link . Oltre a questo si potrebbero inserire nella home page i collegamenti alle pagine più importanti di ciascun gruppo, in modo che un utente trovi subito il servizio di interesse.
Prendendo in considerazione le macroaree del sito definite nel paragrafo 4.2 si può procedere con un'ulteriore analisi, calcolando gli indici di confidence e gli indici di correlazione tra le diverse aree.
Sono stati calcolati, attraverso l'impiego del software WUM, gli indici di confidence relativi alle diverse aree. Riassumiamo i risultati ottenuti nel grafo visualizzato in figura 4.16. Si tratta di un grafo orientato nel quale il verso indica la direzione della relazione, mentre i numeri sugli archi indicano il livello percentuale di confidence. Gli archi con un livello di confidence maggiore sono quelli più marcati.

Figura 4.16 – Livelli significativi di confidence (%) per le diverse macroaree
Abbiamo calcolato anche il coefficiente di correlazione lineare tra le diverse aree. Nel grafo visualizzato nella figura 4.17 possiamo osservare i risultati ottenuti. Si tratta di un grafo non orientato, i numeri sugli archi indicano i diversi coefficienti di correlazione lineare (in percentuale) calcolati per le diverse aree. Anche in questo caso valori più elevati sono contraddistinti da archi più marcati.
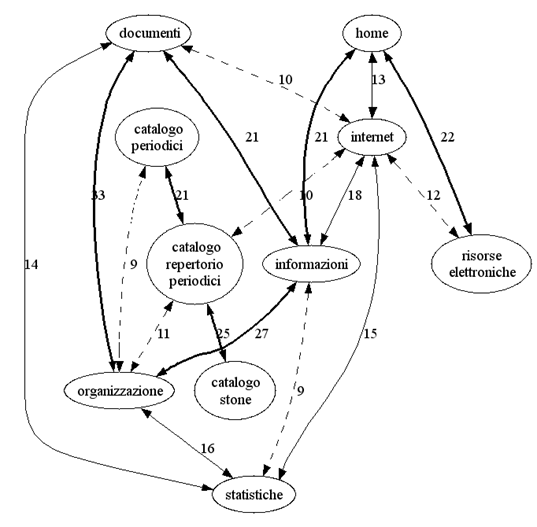
Figura 4.17 – Coefficienti di correlazione lineare (%) calcolati per le diverse aree
Da una prima osservazione dei due grafi, notiamo che le sue misure impiegate non ci hanno condotto agli stessi risultati, ma in qualche modo si assomigliano. Ciò è dovuto al fatto che l'indice di confidence prende in considerazione le sequenze di pagine, mentre il coefficiente di correlazione lineare considera solamente gli insiemi di pagine di ogni sessione utente, senza riferimenti temporali.
Dall'ispezione dei due grafi possiamo trarre alcune considerazioni. I gruppi di diverse aree maggiormente correlate tra loro sono:
• Documenti – Organizzazione – Informazioni
• Internet – Informazioni – Statistiche
• Catalogo Periodici – Catalogo Stone – Catalogo Repertorio Periodici
Ordiniamo le visite alle aree correlate considerando anche le sequenze di visita:
• Organizzazione à Informazioni à Documenti
• Organizzazione à Documenti
• Statistiche à Informazioni à Internet
• Statistiche à Internet
• Catalogo Stone à Catalogo Repertorio Periodici à Catalogo Periodici
Possiamo quindi osservare la direzione di navigazione degli utenti, quando si muovono tra le diverse aree del sito alla ricerca di informazioni. Anche in questo caso, per migliorare la navigazione si potrebbero inserire dei collegamenti alle aree successive delle sequenze.
Tesi di laurea di Gianluca Tavella
Università degli Studi di Milano - Bicocca
Facoltà di Economia
Corso di laurea in Economia e Commercio
Anno Accademico 2003-2004
Home | Software | Analisi | Links | Glossario | Bibliografia