
last update: 25/ jan / 2007
Prosegue la serie di articoli dedicata al monitoraggio dei sistemi in rete andando ad analizzare alcune caratteristiche avanzate di Nagios!
Ci eravamo lasciati nel precedente articolo con la configurazione necessaria al monitoraggio di una rete molto semplice. Vediamo di fare qualche passo ulteriore.
Penso sia lecito ipotizzare che la vostra rete sia un po più complessa di quella finora esemplificata. Per non strafare ipotizziamo un FTP server all'indirizzo 192.168.1.137 come da schema.
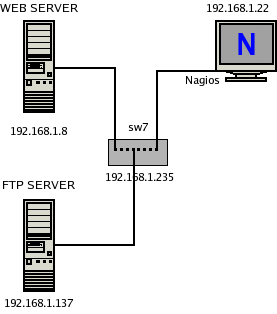
Aggiungiamo quindi l' host ed il servizio nei relativi file:
define host{
use my_host
host_name ftp_server ;Nome del server
alias FTP server
address 192.168.1.137
}
define hostextinfo {
host_name ftp_server
icon_image linux.png
icon_image_alt FTP
vrml_image linux.png
statusmap_image linux.gd2
}
################################################################################
# HOST GROUP DEFINITIONS
################################################################################
# 'linux-boxes' host group definition
define hostgroup{ ; al gruppo è stato aggiunto il server FTP
hostgroup_name linux-boxes
alias Linux Servers
members web_server, ftp_server
}
e ora il servizio da controllare...
define service{
use generic-service ; Name of service template to use
host_name ftp_server
service_description FTP
is_volatile 0
check_period 24x7
max_check_attempts 3
normal_check_interval 10
retry_check_interval 1
contact_groups admins
notification_interval 120
notification_period 24x7
notification_options w,u,c,r
check_command check_ftp
}
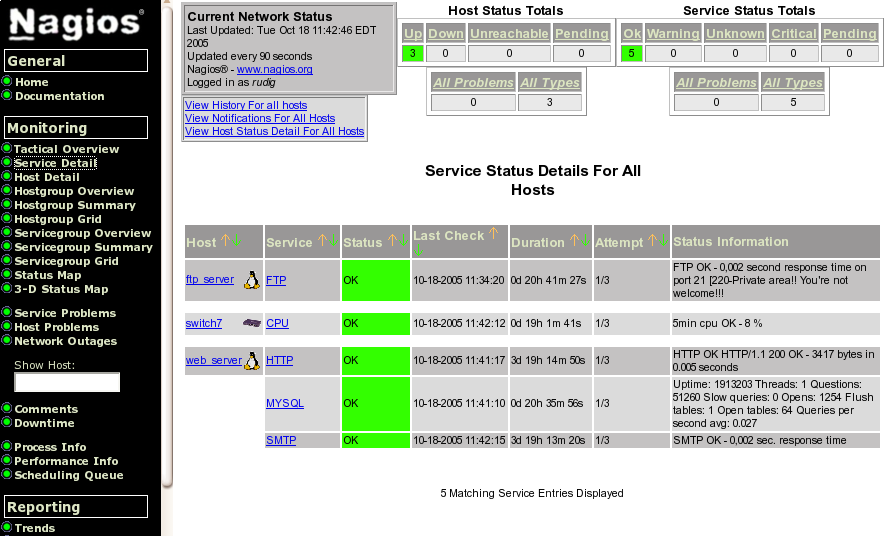
Dopo il solito test e riavvio otteniamo quanto segue
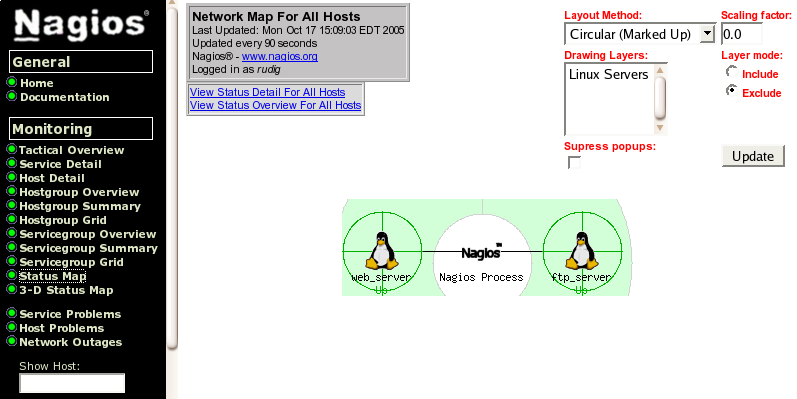
con la corrispondente mappa degli host come si vede nella seguente immagine:
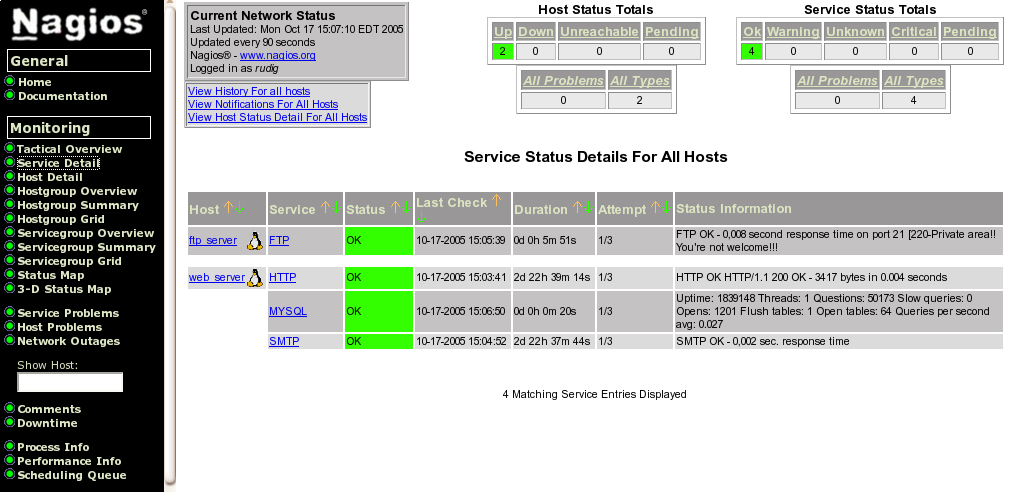
La cosa sarebbe banale, ma ipotizziamo che dopo circa dieci minuti Nagios ci segnali che entrambi gli host siano interrotti. Da una rapida verifica ci accorgiamo che il problema è lo switch a cui entrambi i server sono collegati: Nagios può tenerne conto!
Configuriamo quindi il sistema in modo che controlli anche lo switch e, in caso di problemi a quest'ultimo, ci segnali solo il guasto dell'apparecchiatura e non quello dei server ad essa collegati. Lo switch in questione ha indirizzo 192.168.1.235.
Nel file host oltre ad aggiungere lo switch
# 'switch7' host definition
define host{
use my_host
host_name switch7
alias HP switch 7 armadio principale
address 192.168.1.235
}
define hostextinfo {
host_name switch7
icon_image switch40.png
icon_image_alt Switch 7
vrml_image switch40.png
statusmap_image switch40.gd2
}
bisogna modificare gli altri host per indicare che dipendono da questo nodo utilizzando il parametro parents. Tale informazione fa sì che in caso di problemi di connettività al nodo "padre" non vengano segnalati errori per i nodi "figli". A titolo di esempio mostro l'aggiunta per il solo FTP server:
# 'ftp_server' host definition
define host{
use my_host ; Name of host template to use
host_name ftp_server
alias FTP server
address 192.168.1.137
parents switch7 ; modifica per indicare il nodo padre
}
Non è necessario il monitoraggio dei servizi sullo switch in quanto il solo ping test dello stesso sarebbe sufficiente a determinare se esso è raggiungibile o meno. Lo switch in questione però è di tipo amministrabile da remoto via SNMP e, pur non andando per il momento a prendere in esame questo protocollo, è utile sapere che da la possibilità di eseguire alcuni test su tali apparecchi. Andiamo quindi a costruire un comando che verifica il carico della CPU dello switch e configuriamo il servizio relativo.
Nel file checkcommands.cfg aggiungiamo
define command{
command_name check_sw_cpu
command_line $USER1$/check_snmp -H $HOSTADDRESS$ -C $ARG1$ -o
.1.3.6.1.4.1.11.2.14.11.5.1.9.6.1.0 -t 5 -w $ARG2$ -c $ARG3$ -u % -l "5min cpu"
}
e nel file services.cfg
define service{
use generic-service
host_name switch7
service_description CPU
is_volatile 0
check_period 24x7
max_check_attempts 3
normal_check_interval 5
retry_check_interval 1
contact_groups admins
notification_interval 60
notification_period 24x7
notification_options c,r
check_command check_sw_cpu!public!95:90!100:95
}
Ed ecco quanto ci eravamo prefissi.
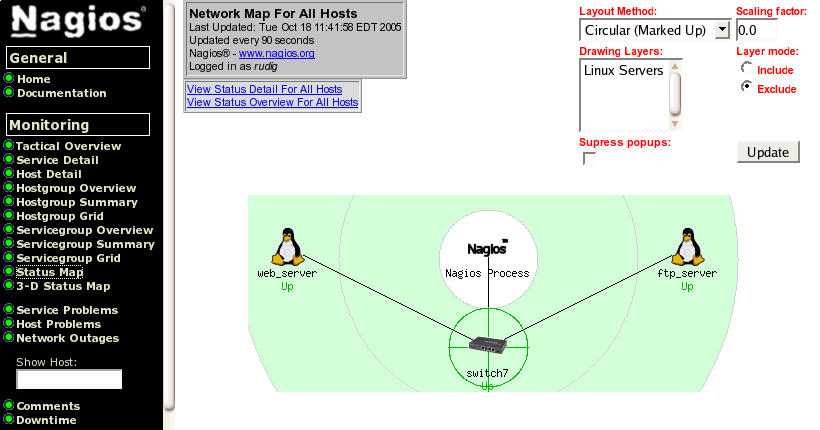
In caso di errore dello switch ci verrà segnalato solo questo e non l'irraggiungibilità degli host ad esso collegati. Un effetto collaterale positivo è che abbiamo anche a disposizione il dato relativo al carico della CPU dello switch che può essere utile per individuare un eventuale problema allo stesso.
Oltre ai test diretti, eseguiti tramite i plugin, Nagios mette
a disposizione altri due sistemi per eseguire test su host
remoti.
Il primo viene utilizzato quando i servizi che si devono
verificare non sono interrogabili da remoto, ad esempio quando
non esiste un modo di verificare da remoto lo spazio libero sul
disco di un' altro PC ed il solo modo di farlo è quello di
verificarlo localmente. La delega di controllo viene demandata ad
un demone chiamato NRPE che viene eseguito sull' host da
controllare.
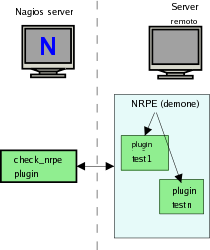
E` un metodo che non ho avuto ancora modo di provare quindi ne espongo solo la teoria come da manuale.
Nagios tramite un plugin di nome check_nrpe contatta il demone remoto di NRPE, che è in ascolto, richiedendo il test. Il demone remoto riceve la richiesta di Nagios ed esegue i test locali tramite i plugin in modo del tutto analogo a quanto farebbe Nagios e restituisce la risposta al plugin chiamante.
Trovo molto più interessante parlare dei test indiretti o passivi in quanto permettono di generare qualsiasi tipo di test senza oltretutto pesare sul server Nagios per l'elaborazione.
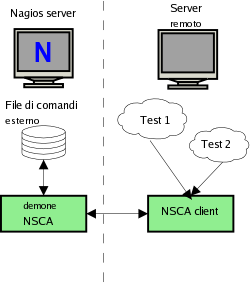
Per l'esecuzione di test passivi è necessaria l'installazione di un applicativo chiamato NSCA client sulla macchina remota e l' installazione del corrispondente demone NSCA, che rimane in ascolto delle comunicazioni sul server Nagios .
Il passaggio dei risultati fra il demone NSCA e Nagios avviene attraverso un file definito external command file (traducibile come "file esterno dei comandi"). Uno degli errori più frequenti, che impediscono il corretto uso dei test passivi, è proprio un' errata impostazione dei permessi del file in questione.
Vediamo quindi tutto il processo di installazione.
Decomprimiamo i sorgenti e compiliamo il programma:
# tar -zxvf nsca-2.4.tar.tar # cd nsca-2.4/ # ./configure ; make all
Poiché il demone viene eseguito tramite il wrapper TCP, ovvero attraverso il demone xinet, dobbiamo apportare alcuni cambiamenti alla configurazione di quest'ultimo: iniziamo con il modificate il file /etc/services aggiungendo la linea seguente:
nsca 5667/tcp # NSCA
Aggiungiamo nella directory /etc/xinetd.d un file chiamato nsca che contenga quanto segue:
# default: on
# description: NSCA Nagios alert
# version.
service nsca
{
disable = no
flags = REUSE
socket_type = stream
protocol = tcp
user = nagios
group = nagios
wait = no
server = /usr/local/nagios/bin/nsca
server_args = -c /usr/local/nagios/etc/nsca.cfg --inetd
log_on_failure += USERID
}
Copiamo il file binario e quello di configurazione a destinazione
# cp nsca-2.4/src/nsca /usr/local/nagios/bin/ # cp nsca-2.4/nsca.cfg /usr/local/nagios/etc/
ed apportatiamo a quest'ultimo le seguenti modifiche:
[...] # ALLOWED HOST ADDRESSES # nella rete due macchine 192.168.1.6-7 sono autorizzate # all'invio di messaggi allowed_hosts=127.0.0.1 allowed_hosts=192.168.1.6 allowed_hosts=172.168.1.7 [...] # DECRYPTION PASSWORD # password da inserire sia sul server che sul client password=mia_pass
A questo punto se non esiste bisogna creare il file esterno dei comandi, aggiungere il corretto utente e gruppo e gestire i permessi:
# touch /usr/local/nagios/var/rw/nagios.cmd # /usr/sbin/groupadd nagiocmd # /usr/sbin/usermod -G nagiocmd nagios # /usr/sbin/usermod -G nagiocmd nobody # chown nagios.nagiocmd /usr/local/nagios/var/rw # chmod u+rwx /usr/local/nagios/var/rw # chmod g+rwx /usr/local/nagios/var/rw # chmod g+s /usr/local/nagios/var/rw
Riavviamo il servizio con il comando
service xinetd restart
ed il server NSCA è pronto ad accogliere i messaggi del client.
Il client, in caso di diversa architettura, va compilato sulla macchina da monitorare. Se avete la stessa versione e distribuzione di GNU/Linux o di UNIX su entrambe le macchine potete semplicemente copiare il file generato nella compilazione precedente.
Per omogeneità di struttura ho creato dei percorsi analoghi a quelli del server Nagios su ciascuno dei due client da monitorare. La serie di comandi che seguono dovrebbe essere esplicativa:
$ pwd /usr/local/nagios [rudig@venus nagios]$ ls -l totale 8 drwxr-xr-x 2 root root 4096 16 mag 15:20 bin drwxr-xr-x 2 root root 4096 16 mag 16:35 etc $ ls bin send_nsca [rudig@venus nagios]$ ls etc send_nsca.cfg
Il file send_nsca.cfg è stato modificato dallo standard inserendo la riga relativa alla password:
[...] # DECRYPTION PASSWORD # password da inserire sia sul server che sul client password=mia_pass
Tutto ciò rappresenta la pura e semplice fase di installazione. Ora è necessario configurare un servizio da controllare.
Si porterà un caso reale come esempio: nasce la necessità di controllare il numero di processi di un determinato applicativo su un server. Questo applicativo è costituito da un processo che elabora una lista di transazioni su un server SQL.
Se nessuna istanza dell'applicativo è attiva le transazioni si accumulano in coda e i dati mostrati non sono più aggiornati. Questo non è un errore grave in quanto una volta fatto ripartire questo motore i dati si riallineano, ma è opportuno che ci sia una segnalazione, un modo da poter riavviare il processo dopo aver verificato il motivo del blocco.
Se invece per un errore vengono avviate più istanze del processo è possibile che la coda venga elaborata fuori sequenza creando degli errori nelle transazioni. Gli errori non sono certi ma probabili e questa condizione va quindi evitata per quanto possibile.
E` quindi desiderabile
E` stato definito il server da controllare in hosts.cfg, un servizio in grado di notificare gli stati in questione nel file services.cfg ed il comando check_null in checkcommands.cfg per impostare un test attivo nullo:
# 'app_server' host definition
define host{
use my_host
host_name app_server ;nome del server
alias Application server
address 192.168.1.6
}
define hostextinfo {
host_name app_server
icon_image linux40.png
icon_image_alt Linux Host
vrml_image linux40.png
statusmap_image linux40.gd2
}
define service{
host_name app_server
service_description test_s_process ;nome arbitrario
is_volatile 1 ; sempre a 1 per nsca
active_checks_enabled 0 ; sempre a 0 per nsca
check_period none
passive_checks_enabled 1 ; è un servizio passivo
max_check_attempts 1
normal_check_interval 10
retry_check_interval 1
contact_groups admins
notification_interval 120
notification_period 24x7
notification_options w,u,c,r
check_command check_null
notifications_enabled 1 ; notifica attiva
}
# 'check_null' command definition by rg
define command{
command_name check_null
command_line $USER1$/check_dummy
}
Poi è stato necessario inventare un metodo per verificare, nel server da controllare, l'attività dell'applicativo in questione tenendo presente che il messaggio che viene trasmesso da send_nsca deve avere il seguente formato:
<nome dell'host> [tabulazione]<nome del servizio>[tab]<codice di ritorno>[tab]<descrizione><carattere di new line>
nell'esempio
app_server test_s_process 0 Tutto OK
dove il codice di ritorno è
0 = se tutto funziona regolarmenteNel nostro caso è stato creato lo script seguente che è ampiamente commentato:
# cat /usr/bin/sendalert.sh
#!/bin/sh
#sendalert.sh
#Script per il test del motore dell'applicativo
#motore_app è il nome del processo sotto controllo, elenco con ps i processi,
filtro con grep quelli che contengono il termine con il nome applicativo e
#conto le linee con wc -l
NUMINST=$(ps ax | grep motore_app | wc -l)
#poichè compare anche la linea precedente nel computo dei processi segnalati da PS
#è necessario eliminare uno dal conteggio.
NUMINST=$[NUMINST-1]
#in base al numero di processi calcolato inviamo il risultato al server nagios
case $NUMINST in
0)
/usr/bin/printf "%s\t%s\t%s\t%s\n" "app_server" "test_s_process" "1" "WARNING! Processo applicativo non attivo" | /usr/local/nagios/bin/send_nsca -H 192.168.1.4 -c /usr/local/nagios/etc/send_nsca.cfg
;;
1)
/usr/bin/printf "%s\t%s\t%s\t%s\n" "app_server" "test_s_process" "0" "OK! Processo applicativo attivo" | /usr/local/nagios/bin/send_nsca -H 192.168.1.4 -c /usr/local/nagios/etc/send_nsca.cfg
;;
2)
/usr/bin/printf "%s\t%s\t%s\t%s\n" "app_server" "test_s_process" "2" "CRITICAL! Troppe istanze Processo applicativo attive" | /usr/local/nagios/bin/send_nsca -H 192.168.1.4 -c /usr/local/nagios/etc/send_nsca.cfg
;;
esac
exit
Per effettuare il controllo è sufficiente schedulare nel cron un'esecuzione dello script appena preparato con un intervallo di tempo appropriato:
# crontab -e
Aggiungere:
## Verifica del processo 05 * * * * /usr/bin/sendalert.sh
Ciò che risulta a video nella pagina relativa ai servizi è una riga come la seguente:
in cui il simbolo dopo il nome del test indica in maniera evidente che il servizio è di tipo passivo.
Il controllo tramite NSCA è particolarmente indicato per il monitoraggio di eventi asincroni. Vorrei portare ad esempio un caso limite che mostra l'adattabilità di Nagios, anche se probabilmente vi sono altri strumenti in grado di effettuare lo stesso tipo di verifiche.
Un modulo dell'applicativo, di cui all'esempio precedente, scambia dei dati con degli applicativi esterni tramite importazione/esportazione di file ASCII. Per il corretto funzionamento di entrambi gli applicativi è necessario che ogni esportazione verso la periferia sia preceduta dalla relativa importazione dei dati precedenti nel sistema centrale. Lo scambio dei dati avviene attraverso un server FTP.
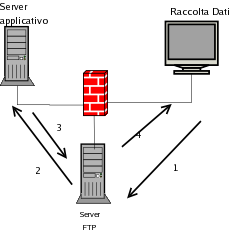
Il tutto può essere così schematizzato:
La soluzione del problema è apparentemente semplice in quanto sarebbe sufficiente verificare la presenza del file di import nel server FTP prima di procedere all'export. La situazione è complicata dal fatto che, per logiche applicative, il nome del file cambia ogni giorno avendo come prefisso la data. Cambia inoltre anche l'ora di trasmissione in quanto la stessa è a discrezione dell'operatore e può avvenire al mattino o al pomeriggio.
Si è pensato quindi di ribaltare il problema: si suppone che sia sempre presente un errore di trasmissione a meno di una corretta trasmissione.
Viene quindi usato un file come semaforo:
Ipotizziamo di chiamare il servizio test_trasf.
In accordo con la sintassi già vista in precedenza prepareremo nel server applicativo un file test_trasf.sem con il seguente contenuto:
app_server test_trasf 1 Warning! File non spediti da raccolta dati
Il file verrà copiato alla mattina in una cartella specificata, come ad esempio /temp/import ed indicherà che il trasferimento dati non è andato a buon fine.
Nel PC di raccolta dati è presente un file con lo stesso nome, ma dal contenuto indicante il corretto trasferimento
app_server test_trasf 0 OK! File spediti da raccolta dati
quindi quando l'utente sincronizza i dati questo file viene trasferito nel server FTP.
Il server applicativo ritira i file dal server applicativo portandoli in /temp/import ove il file semaforo sovrascrive quello che indica l'errore.
Durante gli orari non lavorativi e prima dell'esportazione dati serale viene eseguito lo script seguente che invia i dati al server Nagios tramite NSCA:
sendtrasf.sh #!/bin/sh # per trasf cat /mnt/intra/trasf.sem | /usr/local/nagios/bin/send_nsca -H 172.20.1.4 -c /usr/local/nagios/etc/send_nsca.cfg
Nel server Nagios è stato aggiunto al file service.cfg il servizio che segue:
define service{
host_name app_server
service_description test_trasf
is_volatile 1
active_checks_enabled 0
check_period none
passive_checks_enabled 1
max_check_attempts 1
normal_check_interval 10
retry_check_interval 1
contact_groups admins
notification_interval 120
notification_period 24x7
notification_options w,u,c,r
check_command check_null
notifications_enabled 1 ; Service notifications are enabled
}
Quindi due volte al giorno viene visualizzato lo stato delle importazioni come segue:
In caso di errore viene inviata una notifica al personale di assistenza che può intervenire per richiedere un nuovo invio di dati o bloccare l'esportazione dei dati ed evitare la sovrascrittura di quelli in ingresso.
Come anticipato vi sono sicuramente altri metodi, forse migliori, per eseguire verifiche di questo tipo ma questo esempio è operativo e funzionante in ambiente reale e si è reso più volte utile per evitare errori.
A partire dalla versione 2.0 Nagios possiede una funzionalità di ripristino automatico di un servizio tramite una funzione detta "event handling" ovvero gestione di eventi. Per gestire tale funzione è sufficiente dichiarare all'interno di un servizio un riferimento ad un "event handler". L'esempio che segue è preso pari-pari dal manuale:
define service{
host_name somehost
service_description HTTP
max_check_attempts 4
event_handler restart-httpd
...other service variables...
}
Come vedete la quarta riga richiama una funzione "restart-httpd" che ovviamente serve per riavviare il demone httpd nel caso risultasse indisponibile.
Tale funzione viene definita all'interno di uno dei file di configurazione come ad esempio checkcommands.cfg e conterrà il nome della funzione o del comando atto a gestire il servizio in questione come ad esempio:
define command{
command_name restart-httpd
command_line /usr/local/nagios/libexec/eventhandlers/restart-httpd $SERVICESTATE$ $SERVICESTATETYPE$ $SERVICEATTEMPT$
}
Qui notiamo che viene richiamata una command_line, ma come espone il manuale è un comando creato per l'occasione e che non funziona.
Per meglio chiarire: sicuramente non funziona in nessuna delle distribuzioni Red-Hat o Fedora in cui ho avuto modo di provarlo e concettualmente ciò è corretto. Il fatto è che per ragioni di sicurezza ci siamo dati tanto da fare affinché il demone Nagios e tutti i processi dipendenti avessero scarsi privilegi e permessi in modo da evitare una escalation in caso di intrusioni. Per gestire e riavviare i processi, Nagios deve necessariamente avere dei privilegi più elevati altrimenti non ha il permesso di accesso ai file semaforo dei servizi e a volte nemmeno agli script che gestiscono i servizi stessi.
Non ci sono rimedi ovvi: o si abbassano i livelli di sicurezza o si rinuncia a questa funzionalità. La scelta dipende dalla necessità di continuità del servizio rapportata con i requisiti di sicurezza. Per quel che mi riguarda ho preferito mantenere elevati gli standard di sicurezza ed ho evitato di proseguire i test su questa funzionalità.
La serie di articoli dedicata a Nagios si chiude con i riferimenti bibliografici sottoriportati e con la coscienza di non aver esaurito l'argomento. La serie di articoli sull'amministrazione dei sistemi quidni proseguirà.
Alla prossima!
![]()