
last update: 27/ jun / 2007
In questo articolo si cercherà di evidenziare come RRDTool può essere utile nella gestione dei sistemi.
Round Robin Database tool [http://oss.oetiker.ch/rrdtool/] è un programma open source ideato da Tobias Oetiker che permette di memorizzare misurazioni effettuate nel tempo e ricavarne diagrammi. Si basa sul concetto del round robin una tecnica che utilizza un numero finito di elementi e un puntatore all’elemento corrente. I nuovi elementi vengono aggiunti sovrascrivendo i dati più vecchi. In pratica il database è circolare, una volta raggiunta la fine il puntatore si sposta di nuovo sul primo elemento e inizia a sovrascrivere i dati.
I vantaggi di questa tecnica risiedono proprio nel fatto che essendo noto e predeterminato il numero di elementi che compongono il database le sue dimensioni sono fisse, cosa che sgrava l'amministratore da tutti i problemi di manutenzione relativi alla crescita del database.
Un'altra caratteristica di RRDtool è che i valori non vengono memorizzati quando disponibili ma a intervalli di tempo predeterminati. Se durante l'intervallo di raccolta il dato non è disponibile viene memorizzato al suo posto il valore UNKNOWN (sconosciuto) per quell'intervallo. E' chiaro che un alto numero di valori sconosciuti altera i risultati per cui è molto importante assicurare un flusso costante di dati per l'aggiornamento del database.
Un RRD (Round Robin Database) può contenere qualsiasi tipo di dati numerici, non necessariamente interi, con l'unico limite dato dall'applicabilità della sua struttura circolare.
Il timestamp, ovvero la marcatura temporale, del momento della rilevazione del dato è sempre espressa in numero di secondi trascorsi dal 01/01/1970 (time-epoch) ovvero dalla data convenzionale di creazione di Unix.
RRDtool può essere utilizzato per monitorare qualsiasi tipo di dato sia possibile raccogliere in maniera automatica, ma viene soprattutto utilizzato in congiunzione con il protocollo SNMP.
I sorgenti del programma si possono scaricare da http://people.ee.ethz.ch/~oetiker/webtools/rrdtool/pub/ assieme ai wrappers per vari linguaggi. Cercando su internet potrete sicuramente trovare i binari per le maggiori distribuzioni senza molta fatica.
Le librerie richieste sono libart_lgpl , libpng , zlib, freetype, cgilib coerenti con la versione dei sorgenti scaricata. Potrete comunque trovarle allo stesso link dei sorgenti nella cartella lib/.
Prima di introdurre ulteriore teoria vorrei passare a qualcosa di pratico. Vediamo quindi un esempio di utilizzo parzialmente ripreso da un articolo su [O3 Magazine n.4]. Lo scopo di questa implementazione è di rilevare e tracciare il carico medio del processore di un personal PC.
Creiamo il database loadav.rrd nella directory corrente:
[root@jupiter root]# rrdtool create loadav.rrd --step 10 DS:load:GAUGE:30:0:100 RRA:AVERAGE:0.5:1:9600 \ RRA:AVERAGE:0.5:4:9600 RRA:AVERAGE:0.5:24:6000da cui si ottiene il file:
[root@jupiter root]# ls -l -rw-r--r-- 1 root root 202524 10 mag 16:13 loadav.rrd
Per capire meglio è necessario definire alcuni dei parametri anche se ritengo opportuno invitarvi alla lettura della man page per i dettagli:
Il parametro --step: indica che il database dovrà essere aggiornato ogni x (10 in questo caso) secondi; ovvero rappresenta la risoluzione minima delle letture.
DS: è la variabile di riferimento (data source) in questo caso sarà denominata load ed essendo essa di tipo GAUGE non verrà memorizzato il cambiamento dall'ultimo valore rilevato ma il valore assoluto del valore rilevato. Altri tipi di variabile sono COUNTER consistente di un contatore ad incremento continuo di cui viene immagazzinato il valore per differenza rispetto all'ultima lettura, DERIVE per un contatore decrescente, ABSOLUTE lavora come counter ma immagazina il valore del contatore e non la differenza. Si possono creare più variabili in contemporanea dichiarando più DS per uno stesso archivio.
Il programma attenderà al massimo 30 secondi (15 di attesa effettiva + 15 di tolleranza) per il valore prima di registrare un valore 'UNKNOWN'. Tale attesa è detta heartbeat (letteramente battito cardiaco). Questo è un valore molto delicato in quanto un intervallo lungo significa accettare la possibile perdita di valori intermedi significativi, un intervallo troppo breve significa rischiare di sovraccaricare il sistema e quindi alterare le misurazioni. Il valore è quindi fortemente legato alla natura del dato da misurare.
La variabile può assumere valori compresi fra min 0 e max 100. I valori al di fuori di tale range vengono scartati automaticamente dal sistema in quanto abbiamo imposto che si tratta di valori errati.
Le variabili successive sono riferite ai Round Robin Archives (RRA) cioè sono specifiche relative al dato archiviato. Il termine AVERAGE è riferito alla funzione di consolidamento e significa 'MEDIA' ovvero i dati verranno consolidati con un valore medio (nell'esempio in 3 archivi differenti).
Il primo valore, 0.5, indica che al massimo il 50% dei dati può essere di tipo UNKNOWN. Tale valore che di default è 0 è poco utile quando si riescono a fare misure precise ma mostra il suo senso quanto le rilevazioni dei dati sono molto disturbate.
Nel primo RRA viene indicato che ogni lettura sarà memorizzata fino a 9600 letture poiché ci si attende una lettura entro 15 secondi si crea uno storico di (15 secondi * 9600 letture) = 144.000 secondi memorizzati = 40 ore.
Nel secondo RRA si memorizzano 9600 letture eseguite ogni 15*4 secondi cioè 1 ogni minuto. Per un totale memorizzato di 160 ore.
Con il terzo RRA si archiviano 6000 letture memorizzando un valore ogni 24*15 secondi cioè ogni 6 minuti memorizzando in totale uno storico di 25 giorni.
Questo significa che dai tre archivi potremo analizzare cosa è successo negli scorsi 25 giorni con risoluzioni di 6 minuti, cosà è successo nelle ultime 160 ore con la risoluzione di 1 minuto e cosa è successo nelle ultime 40 ore con il dettaglio ogni 15 secondi.
Il totale delle letture dà la dimensione dell'archivio e in base all' heartbeat si ha la risoluzione e di conseguenza il periodo massimo monitorato.
Per ulteriori dettagli trovate ampie spiegazioni dei parametri nella pagina di manuale che si ottiene con
[root@jupiter root]# man rrdcreate
Finora abbiamo solo creato il database che va popolato con i dati da analizzare:
Creiamo ora un piccolo script che, in maniera abbastanza brutale, va a leggere il carico medio del sistema negli ultimi 1, 5, 15 minuti, il numero dei processi in escuzione/il numero dei processi totali, l'ultimo ID di processo assegnato dal sistema. Lo script estrae poi il carico dell'ultimo minuto memorizzandolo nel database.
Utilizzando un editor (io ho scelto vi)
[root@jupiter root]# vi av.sh
copiate lo script riportato di seguito. Penso sia sufficientemente commentato da evitare ulteriori spiegazioni.
#!/bin/bash while [ 1 ] ; do echo "updating load.." echo "" #estraiamo il carico dell'ultimo minuto CURLOAD=`cat /proc/loadavg | cut -f 1 -d \ ` #memorizziamo il valore ottenuto rrdtool update loadav.rrd N:$CURLOAD #diamo qualche informazione a video CURTIMEIS=`date` echo "updated at "$CURTIMEIS" with "$CURLOAD echo "" #attendiamo 10 secondi prima di ripetere il tutto sleep 10s done
Ora trasformate il file in eseguibile ed avviatelo
[root@jupiter root]# chmod +x av.sh [root@jupiter root]# ./av.sh
Riporto uno stralcio dell'output tagliato per evitarvi la monotonia di migliaia di righe sempre uguali
[..] updated at mer mag 10 16:28:22 EDT 2006 with 0.00 updating load.. updated at mer mag 10 16:28:33 EDT 2006 with 0.00 updating load.. updated at mer mag 10 16:28:43 EDT 2006 with 0.00
Dopo un po di tempo ho interrotto manualmente (ctrl+C) il programmino. Da buon curioso ho verificato che il file ha effettivamente dimensione fissa e riporta l'ora dell'ultimo aggiornamento.
[root@jupiter root]# ls -l -rw-r--r-- 1 root root 202524 10 mag 16:29 loadav.rrdSempre da buon curioso ho voluto verificare come la dimensione del file fosse dipendente dai parametri di creazione. Chiaramente essendo tanto pigro quanto curioso non ho letto i sorgenti ma mi sono arrangiato con un paio di test per un po di reverse engineering. Di seguito vedete le istruzioni di creazione di 3 RRA con rispettivamente 1000, 2000 e 1 elemento e di seguito la dimensione del file ottenuto:
[root@giacomini mytests]# rrdtool create loadav2.rrd --step 10 DS:load:GAUGE:30:0:100 RRA:AVERAGE:0.5:1:1000 -rw-r--r-- 1 root root 8540 12 mag 12:11 loadav2.rrd [root@giacomini mytests]# rrdtool create loadav2.rrd --step 10 DS:load:GAUGE:30:0:100 RRA:AVERAGE:0.5:1:2000 -rw-r--r-- 1 root root 16540 12 mag 12:11 loadav2.rrd [root@giacomini mytests]# rrdtool create loadav2.rrd --step 10 DS:load:GAUGE:30:0:100 RRA:AVERAGE:0.5:1:1 -rw-r--r-- 1 root root 548 12 mag 12:13 loadav2.rrdDai numeri si evince che esiste un overhead fisso di 540 bytes dovuto probabilmente alle intestazioni ed ai puntatori, più 8 bytes per ogni dato:
Ora abbiamo ottenuto un database con dei dati. Sfrutto quindi il comando fetch per visualizzarne il contenuto che è mostrato di seguito troncato per leggibilità:
[root@jupiter root]# rrdtool fetch loadav.rrd AVERAGE 1147291750: nan 1147291760: nan 1147291770: nan 1147291780: nan [..] 1147292000: nan 1147292010: nan 1147292020: nan 1147292030: nan 1147292040: 6.3000000000e-01 1147292050: 5.4000000000e-01 1147292060: 4.5800000000e-01 1147292070: 3.8700000000e-01 [..] 1147292910: 0.0000000000e+00 1147292920: 0.0000000000e+00 1147292930: 0.0000000000e+00 1147292940: 0.0000000000e+00 1147292950: 0.0000000000e+00 1147292960: nan 1147292970: nanVisto così l'estratto delle righe memorizzate non ci trasmette un gran numero di informazioni, e il dump in XML non è molto più esaustivo anche se perlomeno contiene alcuni elementi relativi al DS che aiutano nella comprensione dei dati:
[root@jupiter root]# rrdtool dump loadav.rrd
<!-- Round Robin Database Dump -->
<rrd>
<version> 0001 </version>
<step> 10 </step> <!-- Seconds -->
<lastupdate> 1147292953 </lastupdate> <!-- 2006-05-10 16:29:13 EDT -->
<ds>
<name> load </name>
<type> GAUGE </type>
<minimal_heartbeat> 30 </minimal_heartbeat>
<min> 0.0000000000e+00 </min>
<max> 1.0000000000e+02 </max>
<!-- PDP Status -->
<last_ds> UNKN </last_ds>
<value> 0.0000000000e+00 </value>
<unknown_sec> 0 </unknown_sec>
</ds>
<!-- Round Robin Archives -->
<rra>
<cf> AVERAGE </cf>
<pdp_per_row> 1 </pdp_per_row> <!-- 10 seconds -->
<xff> 5.0000000000e-01 </xff>
<cdp_prep>
<ds><value> NaN </value> <unknown_datapoints> 0 </unknown_datapoints></ds>
</cdp_prep>
<database>
<!-- 2006-05-09 13:49:20 EDT / 1147196960 --> <row><v> NaN </v></row>
<!-- 2006-05-09 13:49:30 EDT / 1147196970 --> <row><v> NaN </v></row>
<!-- 2006-05-09 13:49:40 EDT / 1147196980 --> <row><v> NaN </v></row>
<!-- 2006-05-09 13:49:50 EDT / 1147196990 --> <row><v> NaN </v></row>
<!-- 2006-05-09 13:50:00 EDT / 1147197000 --> <row><v> NaN </v></row>
<!-- 2006-05-09 13:50:10 EDT / 1147197010 --> <row><v> NaN </v></row>
<!-- 2006-05-09 13:50:20 EDT / 1147197020 --> <row><v> NaN </v></row>
<!-- 2006-05-09 13:50:30 EDT / 1147197030 --> <row><v> NaN </v></row>
<!-- 2006-05-09 13:50:40 EDT / 1147197040 --> <row><v> NaN </v></row>
[...]
<!-- 2006-05-10 16:24:00 EDT / 1147292640 --> <row><v> 3.6250000000e-02 </v></row>
<!-- 2006-05-10 16:28:00 EDT / 1147292880 --> <row><v> 1.9250000000e-02 </v></row>
</database>
</rra>
</rrd>
Quindi per avere un qualcosa di realmente utile ho creato il grafico:
[root@jupiter root]# rrdtool graph /var/www/html/loadav.png DEF:load=loadav.rrd:load:AVERAGE LINE1:load#0000ff:Load --start -1h 480x155Avendo avuto l'accortezza di indirizzare il risultato sulla directory del web server locale del mio PC posso visualizzarlo con il browser (in alternativa potete indirizzare il grafico alla directory corrente e visualizzare il tutto con un visualizzatore grafico qualsiasi):
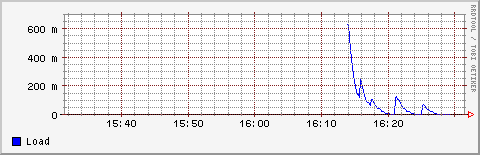
Volendo un intervallo temporale più ristretto (ovvero un maggior dettaglio):
[root@jupiter root]# rrdtool graph /var/www/html/loadav.png DEF:load=loadav.rrd:load:AVERAGE LINE1:load#0000ff:Load --start -40m --end -30m 480x155si ottiene:
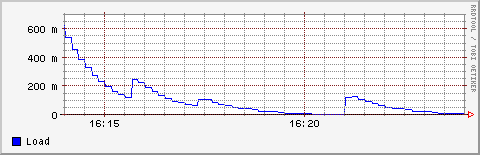
Vediamo ora un grafico su dati diversi con un po' di matematica all'interno:
[root@giacomini mytests]# rrdtool graph /var/www/html/loadav.png DEF:load=loadav.rrd:load:AVERAGE CDEF:loadsec=load,1000,\* LINE2:loadsec#ff0000:Load/sec LINE1:load#0000ff:Load --start -1h 480x155
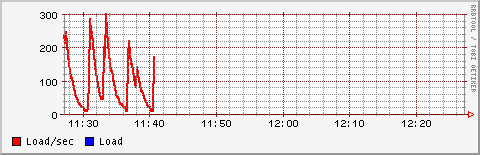
Una nota: Quando si lavora con variabili di tipo contatore bisogna ricordarsi del fenomeno di riazzeramento (wrap), ovvero del fatto che il contatore arrivato al limite computabile (dipendente dal numero di bits che si intende usare nei conteggi) si azzera e ricomincia il conteggio. Rrdtool compensa automaticamente questo tipo di problemi quando la differenza tra due variabili è negativa ovvero quando si è presentato il fenomeno del passaggio per lo zero. Bisogna comunque fare attenzione di non lavorare con un basso numero di bits su intervalli di tempo troppo lunghi in quanto la nuova lettura dopo il passaggio per lo zero potrebbe assumere un valore più alto della lettura precedente. In tale caso la differenza sarebbe maggiore di zero e il riazzeramento non verrebbe intercettato dando luogo ad errori di misura. I valori di min e max possono essere utili per intercettare e scartare tali valori anomali.
Chiudo qui queste brevi note su RRDTool invitando coloro che trovano antipatica la riga di comando, a provare l'ottima interfaccia grafica per questo tool fornita da CACTI: un progetto open source nato appunto per semplificare l'approccio a RRDTool.
![]()