Un insieme di documenti collegati fra loro e sparsi su milioni di elaboratori
forma un ipertesto (hypertext),
cioè un testo che viene percorso in modo non lineare. Il Web ha diverse
caratteristiche che hanno contribuito al suo enorme successo:
architettura di tipo client-server:
ampia scalabilità;
adatta ad ambienti di rete;
architettura distribuita:
perfettamente in linea con le esigenze di gestione di un ipertesto;
architettura basata su standard di pubblico dominio:
possibilità per chiunque di proporre una implementazione;
uguali possibilità di accesso per tutte le piattaforme di
calcolo;
capacità di gestire informazioni di diverso tipo (testo, immagini,
suoni, filmati, realtà virtuale, ecc.):
grande interesse da parte di tutti gli utenti.
I documenti che costituiscono l'ipertesto gestito dal Web sono detti pagine
Web, e possono contenere, oltre a normale testo formattato, anche:
rimandi (detti link o hyperlink)
ad altre pagine Web;
immagini fisse o in movimento;
suoni;
scenari tridimensionali interattivi;
codice eseguibile localmente.
L'utilizzo del Web è semplicissimo:
un utente legge il testo della pagina, vede le immagini, ascolta la
musica, ecc.;
se seleziona col mouse un link (che di solito appare come una parola
sottolineata e di diverso colore) la pagina di partenza viene sostituita
sullo schermo da quella relativa al link selezionato.
Si noti che la nuova pagina può provenire da qualunque parte del
pianeta.
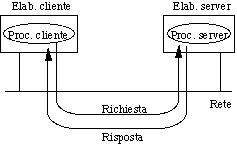
2) Architettura client-server del Web
Il Web è una architettura software di tipo client-server,
nella quale sono previste due tipologie di componenti software: il client
e il server, ciascuno avente compiti
ben definiti.
2.1) Client
Il client (o user agent)
è lo strumento a disposizione dell'utente che gli permette l'accesso
e la navigazione nell'ipertesto del Web.
Esso ha varie competenze:
trasmettere all'opportuno server le richieste di reperimento dati che derivano
dalle azioni dell'utente;
ricevere dal server le informazioni richieste;
visualizzare il contenuto della pagina Web richiesta dall'utente, gestendo
in modo appropriato tutte le tipologie di informazioni in esse contenute;
consentire operazioni locali sulle informazioni ricevute
(ad esempio salvarle su disco, stamparle).
I client vengono comunemente chiamati browser
(sfogliatori). Gli esempi più noti di browser grafici sono:
In generale è troppo complicato e costoso (sarebbero necessari
aggiornamenti troppo frequenti) sviluppare un browser che sappia gestire
direttamente tutti i tipi di informazioni presenti sul Web,
poiché essi sono in continuo e rapido aumento.
Per questa ragione, di norma i browser gestiscono direttamente solo
alcune tipologie di informazioni, quali:
testo formattato;
immagini fisse;
codice eseguibile.
Viceversa, di norma gli altri tipi di informazioni vengono gestiti in uno
(o entrambi) dei seguenti modi:
consegnandoli a un programma esterno
(helper)
che provvederà alla corretta gestione (ad esempio, un file contenente
un filmato verrà consegnato a un programma per il playback di
filmati);
se il browser ha un'architettura modulare le sue funzionalità
possono essere estese per mezzo di
plug-in,
ossia librerie di codice eseguibile specializzato che possono essere caricate
in memoria secondo le necessità. In questa situazione, se il necessario
plug-in è installato, il browser provvede a caricarlo e gli affida
la gestione delle informazioni da trattare.
Esistono anche browser di testo come
Lynx che ignorano
tutti i riferimenti a immagini, suoni, video e colori. Utilizzare un browser
di testo può essere utile per caricare molto più rapidamente le
pagine web ed accedere ad informazioni.
Esistono anche browser audio e braille per permettere l'utilizzo di Internet
anche alle persone non vedenti ed i nuovi standard per la realizzazione di
documenti web tengono in considerazione queste necessità.
Il server è tipicamente un processo in esecuzione
su un elaboratore. Esso, di norma, è sempre in esecuzione (tranne
che in situazioni eccezionali) ed ha delle incombenze molto semplici, almeno
in linea di principio. Infatti deve:
rimanere in ascolto di richieste da parte dei client;
fare del suo meglio per soddisfare ogni richiesta che arriva:
se possibile, consegnare il documento richiesto;
altrimenti, spedire un messaggio di notifica di errore
(documento non esistente, documento protetto, ecc.).
Nonostante la apparente semplicità di tale compito, la realizzazione
di un server non è banale, perché:
deve fare il suo lavoro nel modo più efficiente possibile, dunque
deve essere implementato con un occhio di riguardo alle prestazioni;
deve essere in grado di gestire molte richieste contemporaneamente, e
mentre fa questo deve continuare a rimanere in ascolto di nuove richieste.
Il secondo requisito in particolare implica una qualche forma di concorrenza
nel lavoro del server. Essa si può ottenere in vari modi, anche
in funzione delle caratteristiche del sistema operativo sottostante. Le
due tecniche più diffuse sono descritte nel seguito.